در حال خواندن: معرفی جدید ترین هوش مصنوعی Z ، مدل GLM 5 رونمایی شد!
-
01
معرفی جدید ترین هوش مصنوعی Z ، مدل GLM 5 رونمایی شد!
معرفی جدید ترین هوش مصنوعی Z ، مدل GLM 5 رونمایی شد!

درست همین امروز بود که وقتی به شکل رندوم به ابزار ها و مدل های هوش مصنوعیم سر می زدم، دیدم که یار وفادار (همواره رایگان) ما یعنی Z.ai با یک ظاهر جدید داره حرف از مدل جدیدش می زنه. جدیدترین هوش مصنوعی Z ، مدل GLM 5 رونمایی شد!بله، همین امروز نسخه 5 خودش رو منتشر کرد!
تاریخ انتشار 11 فوریه
رفتم بیشتر تحقیق کردم و دیدم که کاملاً صحیح است. همه برنامه نویس ها وقتی خبر از نسخه جدید یک نرم افزار یا مدل یا هرچی می بینن، اولین چیزی که توجهشون رو جلب می کنه، عدد نسخه ها هست (قطعاً اصطلاح دقیقتری براش دارن)، که وقتی در یک نسخه شاهد تغییر یا جهش از 4.7 به 5 هستیم چه معنا و مفهومی دارد.
 درست بعد از خواندن ویژگی ها و بنچمارک های این مدل از افزایش تغریباً دو برابری پارامتر ها از مدل 4.7 با 355 میلیارد تا 5 با 744 میلیارد و تعداد پارامتر های فعال از 32 میلیارد تا 40 میلیارد، رفتم سراغ نمودار های تحلیلی و مقایسه ای بین این مدل با شرکت های حال حاضر و اونجا بود که دیدم چه نوستراداموسی بودم برا خودم که به هرکی می رسیدم می گفتم از z ai استفاده کن!
درست بعد از خواندن ویژگی ها و بنچمارک های این مدل از افزایش تغریباً دو برابری پارامتر ها از مدل 4.7 با 355 میلیارد تا 5 با 744 میلیارد و تعداد پارامتر های فعال از 32 میلیارد تا 40 میلیارد، رفتم سراغ نمودار های تحلیلی و مقایسه ای بین این مدل با شرکت های حال حاضر و اونجا بود که دیدم چه نوستراداموسی بودم برا خودم که به هرکی می رسیدم می گفتم از z ai استفاده کن!
البته فارغ از این نوشابه باز کردن ها باید دونست که تعصب پیدا کردن به مدل خاصی، دقیقاً همون خواسته ایه که بازاریابی ها می خواهند و بعداً با همین تعصب مدل ها را با هر قیمتی می توانند بفروشند، پس از این بحثا دوری کنید و صرفاً از هر ابزاری که به بهترین شکل کار رو راه می اندازد استفاده کنید!
به طور کلی می توان گفت هوش مصنوعی های چینی بازار رو دارن جذاب می کنن، پس بهتره از یک طیف از ابزار بهره برد.
معماری جدید
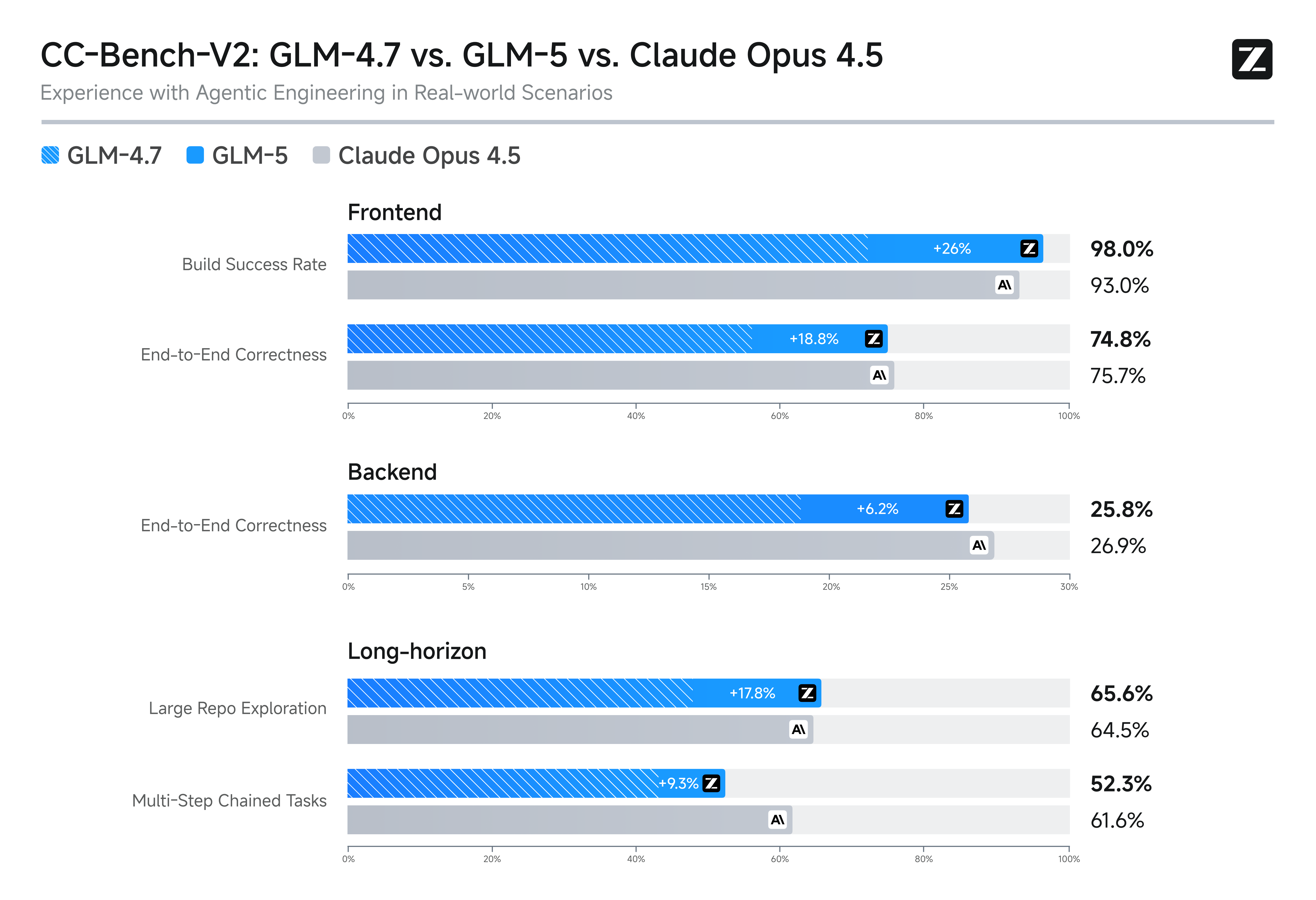
برگردیم به موضوع، مهمترین این بخش ها توسعه چارچوب یادگیری جدیدی به اسم Slime هست که این مدل را به یک مدل توسعه دهنده در مرز های یادگیری ماشین قرار می دهد، به طور کلی این چارچوب که بر اساس RL (Reinforced Learning) هست، منجر به بهبود دو زمینه می شود، یادگیری با بهرهوری بالاتر، تولید داده ها به صورت منعطف تر. البته ما در مقالاتمون مفصل معماری رو از نظر فنی تحلیل می کنیم اما الآن برای شروع خبر بریم به سراغ نمودار های تحلیلی دیگر که بسیار گویاتر بیانگر خیلی مسائل هستند.
| Benchmark | GLM-5
(Thinking) |
GLM-4.7
(Thinking) |
DeepSeek-V3.2
(Thinking) |
Kimi K2.5
(Thinking) |
Claude Opus 4.5
(Extend Thinking) |
Gemini 3.0 Pro
(High Thinking Level) |
GPT-5.2
(xhigh) |
|---|---|---|---|---|---|---|---|
| Reasoning | |||||||
| Humanity’s Last Exam | 30.5 | 24.8 | 25.1 | 31.5 | 28.4 | 37.2 | 35.4 |
|
Humanity’s Last Exam w/ Tools |
50.4 | 42.8 | 40.8 | 51.8 | 43.4* | 45.8* | 45.5* |
| AIME 2026 I | 92.7 | 92.9 | 92.7 | 92.5 | 93.3 | 90.6 | – |
| HMMT Nov. 2025 | 96.9 | 93.5 | 90.2 | 91.1 | 91.7 | 93.0 | 97.1 |
| IMOAnswerBench | 82.5 | 82.0 | 78.3 | 81.8 | 78.5 | 83.3 | 86.3 |
| GPQA-Diamond | 86.0 | 85.7 | 82.4 | 87.6 | 87.0 | 91.9 | 92.4 |
| Coding | |||||||
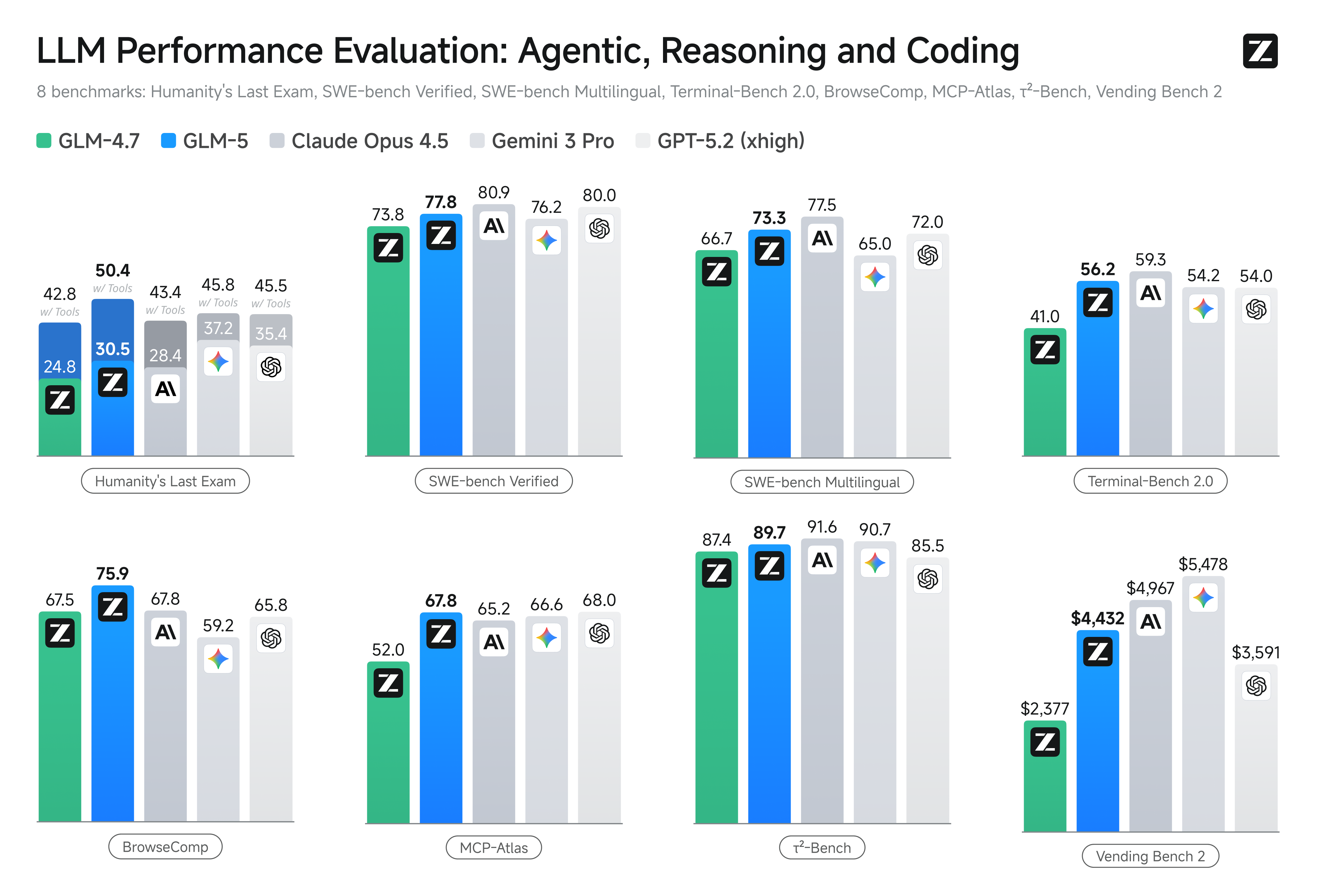
| SWE-bench Verified | 77.8 | 73.8 | 73.1 | 76.8 | 80.9 | 76.2 | 80.0 |
| SWE-bench Multilingual | 73.3 | 66.7 | 70.2 | 73.0 | 77.5 | 65.0 | 72.0 |
|
Terminal-Bench 2.0 Terminus-2 |
56.2 /
60.7† |
41.0 | 39.3 | 50.8 | 59.3 | 54.2 | 54.0 |
|
Terminal-Bench 2.0 Claude Code |
56.2 /
61.1† |
32.8 | 46.4 | – | 57.9 | – | – |
| CyberGym | 43.2 | 23.5 | 17.3 | 41.3 | 50.6 | 39.9 | – |
| General Agent | |||||||
| BrowseComp | 62.0 | 52.0 | 51.4 | 60.6 | 37.0 | 37.8 | – |
|
BrowseComp w/ Context Manage |
75.9 | 67.5 | 67.6 | 74.9 | 67.8 | 59.2 | 65.8 |
| BrowseComp-Zh | 72.7 | 66.6 | 65.0 | 62.3 | 62.4 | 66.8 | 76.1 |
| τ²-Bench | 89.7 | 87.4 | 85.3 | 80.2 | 91.6 | 90.7 | 85.5 |
|
MCP-Atlas Public Set |
67.8 | 52.0 | 62.2 | 63.8 | 65.2 | 66.6 | 68.0 |
| Tool-Decathlon | 38.0 | 23.8 | 35.2 | 27.8 | 43.5 | 36.4 | 46.3 |
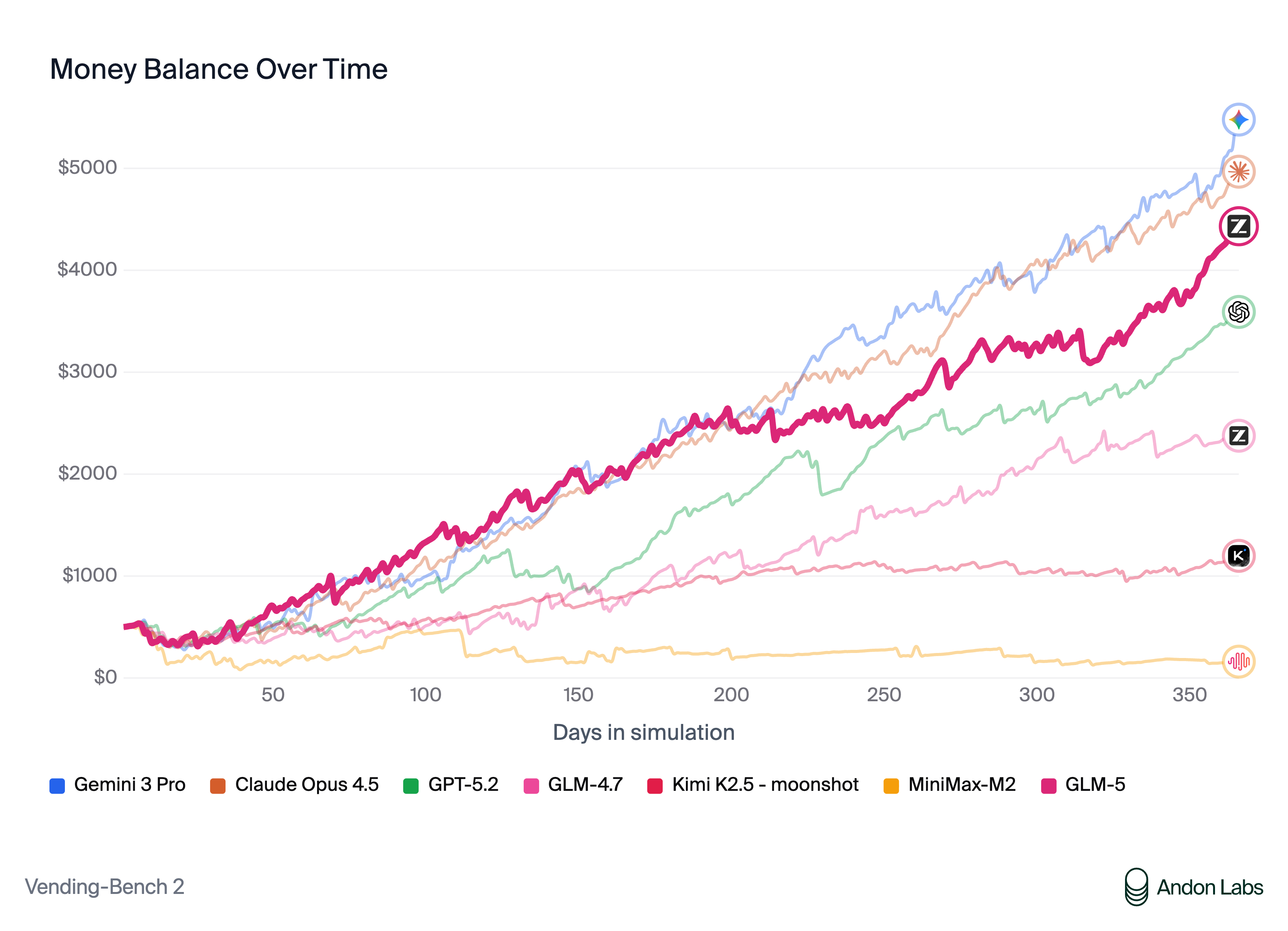
| Vending Bench 2 | $4,432.12 | $2,376.82 | $1,034.00 | $1,198.46 | $4,967.06 | $5,478.16 | $3,591.33 |
سخن آخر
با دنبال داشتن یک مرجع معتبر از اخبار و اطلاعات دقیق و به لحظه از جدیدترین مدل ها و مقالات به روز بمانید.
با آخرین و مهمترین اخبار بهروز بمانید
پست قبلی
پست بعدی










استودیو هام