
در حال خواندن: معمای غیرقابل حل؟ آزمونی که هوش مصنوعی را به زانو درآورد!
-
01
معمای غیرقابل حل؟ آزمونی که هوش مصنوعی را به زانو درآورد!
معمای غیرقابل حل؟ آزمونی که هوش مصنوعی را به زانو درآورد!

آیا واقعاً هوش مصنوعی داره جای ما رو میگیره یا فقط ادای باهوشها رو درمیاره؟
بیایید روراست باشیم؛ این روزها هر جا رو نگاه میکنیم، تیترهای “هوش مصنوعی جایگزین انسان شد” یا “مدل جدید X همه چیز را تغییر داد” رو میبینیم. اما صبر کنید! یه جای کار میلنگه. اگر این مدلها اینقدر خفن هستن، پس چرا هنوز توی حل کردن یه سری پازل رنگی ساده که شاید خواهرزاده ۵ سالهتون هم بتونه حل کنه، گیر میکنن؟
امروز میخوایم پرونده یکی از خفنترین، ترسناکترین و البته جذابترین چالشهای دنیای AI رو باز کنیم: بنچمارک ARC-AGI.
چیزی که خالقش، فرانسوا شوله (François Chollet)، اون رو طراحی کرده تا مچِ مدلهای زبانی رو بگیره و بهمون نشون بده که “حفظ کردن کل اینترنت” با “فهمیدن”، زمین تا آسمون فرق داره! آمادهاید ببینید چطور غولهای تکنولوژی جلوی چند تا مربع رنگی زانو میزنن؟
ARC-AGI: وقتی هوش مصنوعی باید واقعاً فکر کنه، نه تقلب!
خب، بذارید یه سوال ساده بپرسم. اگه کل کتابای دنیا رو حفظ باشید، یعنی باهوشید؟ فرانسوا شوله (François Chollet)، که احتمالاً اسمش رو شنیدید (همون نابغهای که کتابخونه Keras رو ساخته)، میگه: نه داداش، اشتباه زدی!
داستان ARC (Abstraction and Reasoning Corpus) دقیقاً همینه. این بنچمارک شبیه اون تستهای هوش تصویری (مثل ماتریسهای ریون) هست که احتمالاً همهمون حداقل یک بار باهاشون کلنجار رفتیم. یه سری شبکه شطرنجی رنگی، چند تا مربع اینور و اونور، و یه الگو که باید کشفش کنی.
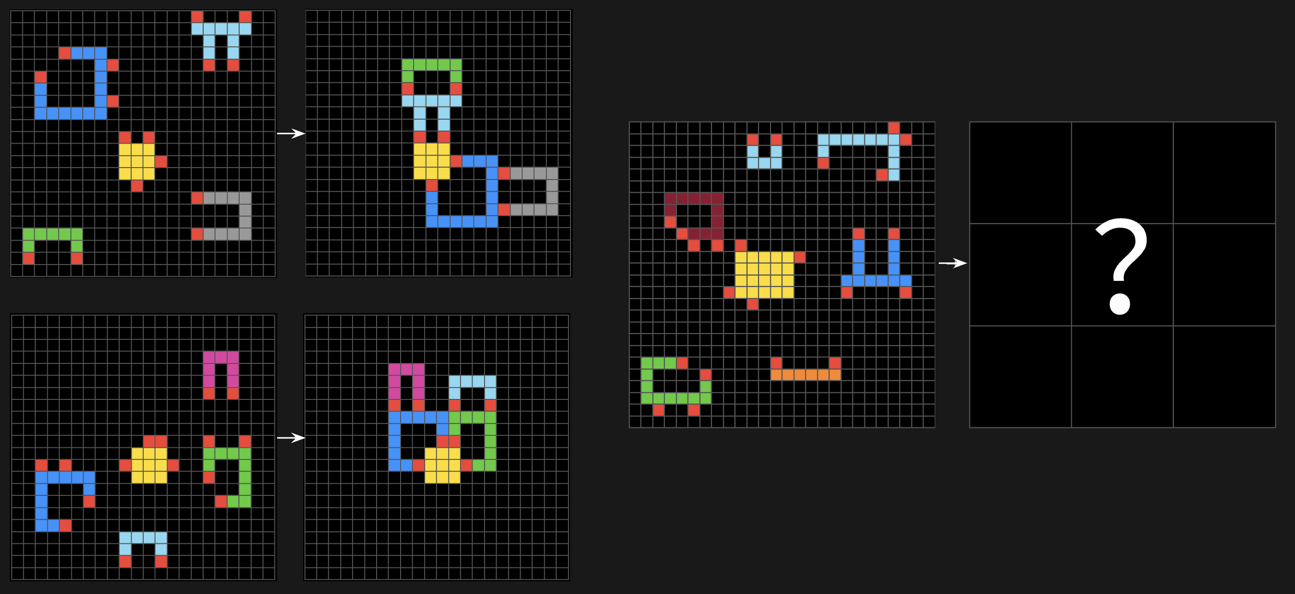
فرقش با بقیه چیه؟ چرا مدلها هنگ میکنن؟
توی مدلهای زبانی بزرگ (LLM) مثل GPT-4 یا کلود، ماجرا اینه که این دوستان تقریباً همه متنهای اینترنت رو دیدن. وقتی ازشون یه سوال کدنویسی میپرسید، احتمال زیاد قبلاً هزار بار شبیهش رو توی گیتهاب دیدن. این اسمش “هوش” نیست، این یه جورایی “حافظه خیلی خفن” یا “تقلب مجازه”!
اما ARC مچشون رو میگیره! چطوری؟
-
مسائل کاملاً جدید (Novel Tasks): معماهایی که توی این آزمون هست، هیچوقت توی دادههای آموزشی مدلها نبوده. یعنی مدل نمیتونه از روی دست بقیه نگاه کنه.
-
قانون بازی رو همون لحظه یاد بگیر: به مدل ۳ تا مثال نشون میدن (مثلاً: “ببین، اینجا رنگ آبی تبدیل شد به قرمز”). بعد یه نمونه چهارم میذارن جلوش و میگن: “حالا که قانون رو فهمیدی، این یکی رو حل کن.”
-
استدلال خالص: اینجا دیگه با “حدس زدن کلمه بعدی” کار راه نمیفته. مدل باید بتونه انتزاع (Abstraction) کنه؛ یعنی بفهمه “آها، اینجا قانونش اینه که اشیاء همرنگ باید به سمت راست حرکت کنن”.
خلاصه بگم، ARC-AGI داره فریاد میزنه: “من برام مهم نیست چقدر کتاب خوندی، بهم نشون بده چقدر میتونی یاد بگیری!”
انسان ۸۵٪ – هوش مصنوعی ۳۴٪: یه باخت سنگین!
بذارید با عدد و رقم حرف بزنیم که قضیه روشنتر بشه. اگر همین الان خودِ شما برید سراغ تستهای ARC (که تو سایتش هست)، به احتمال زیاد خیلی راحت میتونید حدود ۸۵ درصد سوالات رو حل کنید. چرا؟ چون مغز ما از بچگی یاد گرفته که دنیا چه شکلیه؛ میدونیم اگر یه چیزی رفت پشت دیوار، غیب نمیشه (پایداری شیء)، یا میفهمیم “خط راست” با “دایره” فرق داره.
اما هوش مصنوعی؟ فعلا فاجعه!
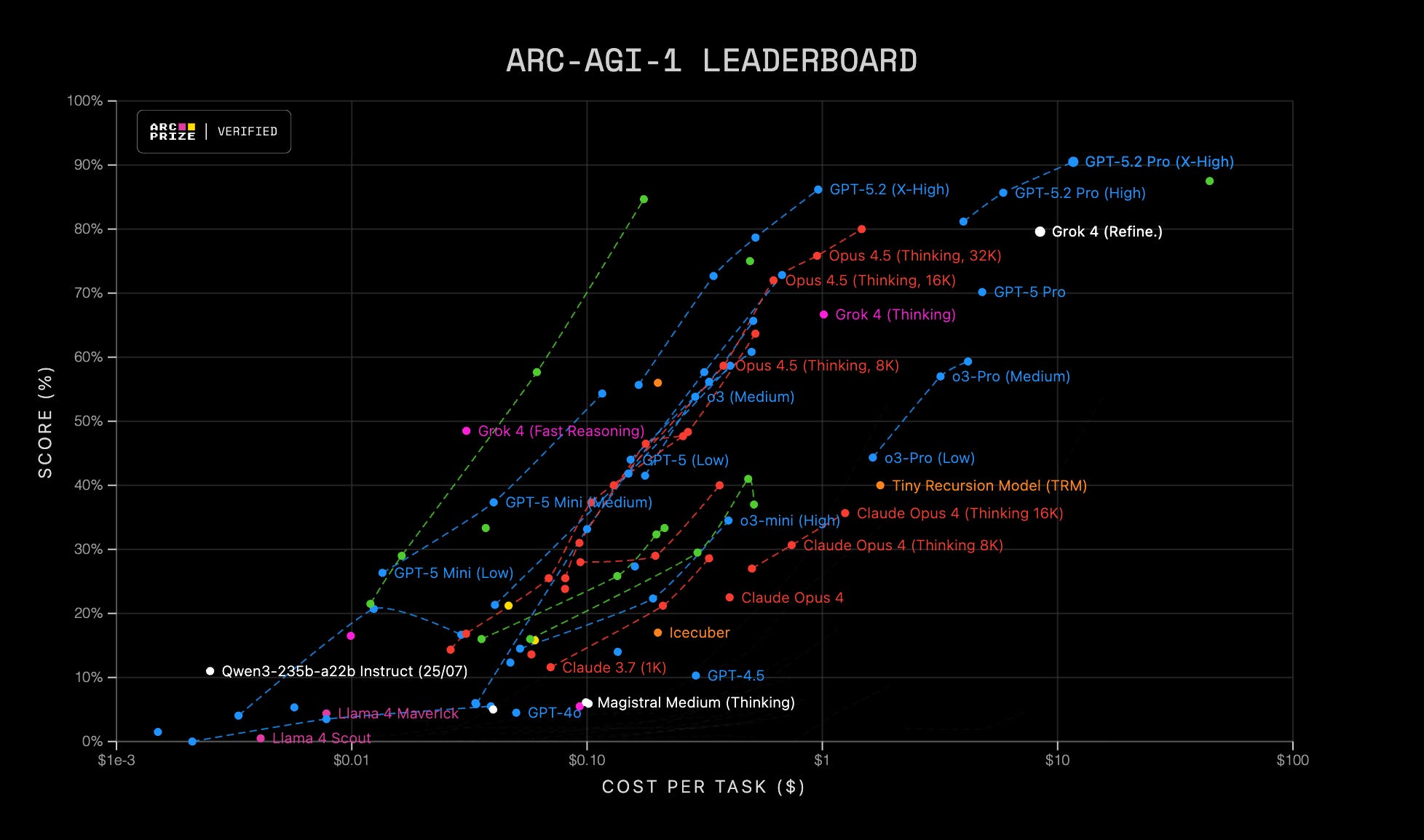
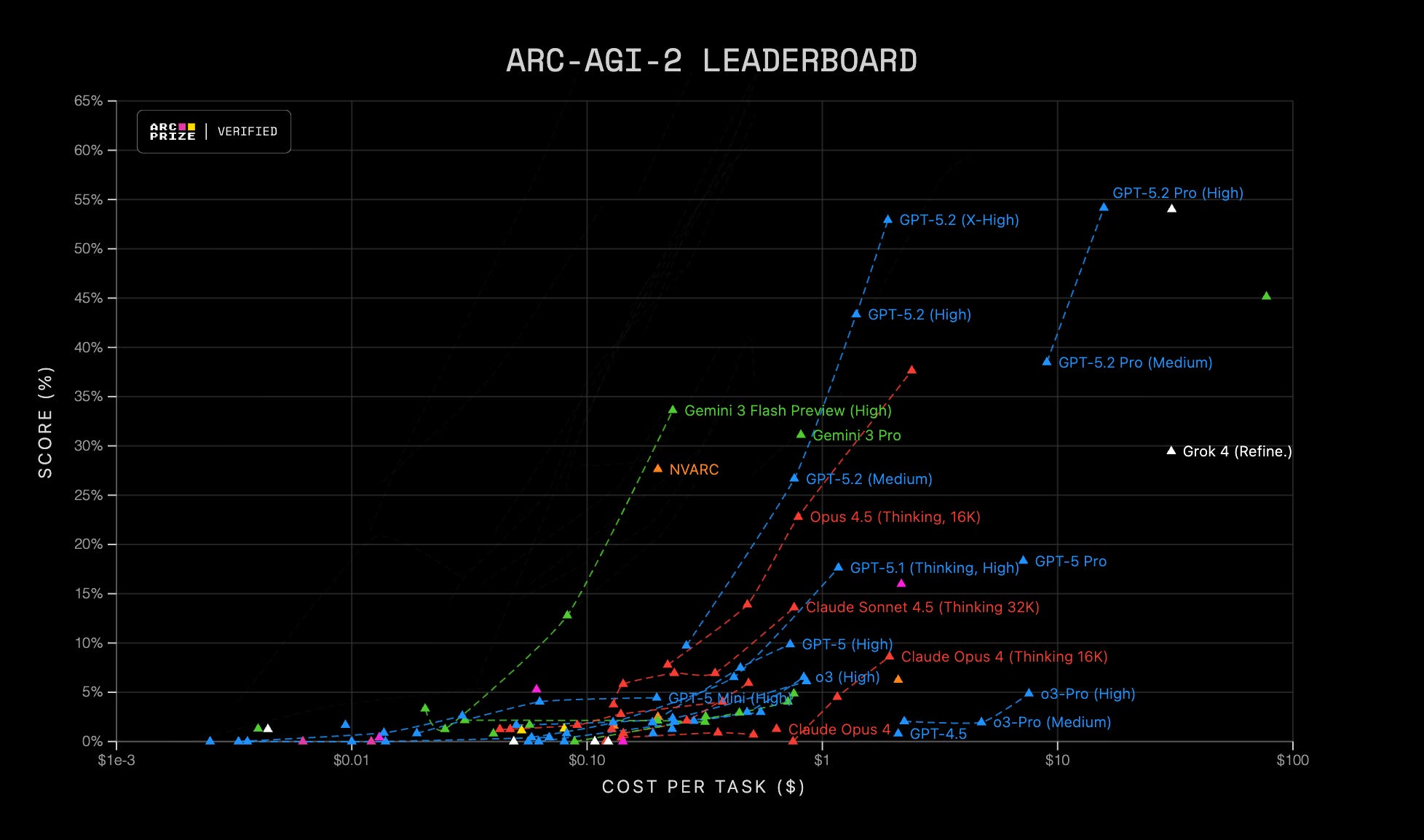
تا همین اواخر، شاخترین مدلهای زبانی (که ادعای خدایی میکنن!) به زور و زحمت تونسته بودن به ۳۴ درصد برسن. یعنی یه بچه دبستانی تو حل پازلهای منطقی، هوش مصنوعی گوگل و OpenAI رو قورت میده!
چرا اینقدر سخته؟ مگه فقط چند تا مربع رنگی نیست؟
نکته دقیقاً همینجاست! ما انسانها یه چیزی داریم به اسم “دانش پایه” (Core Knowledge). ما مفاهیمی مثل:
-
تداوم اشیاء: (این توپه هنوز همون توپه، فقط رنگش عوض شد).
-
اعداد و شمارش: (اینجا سه تا نقطه هست، اونورم باید سه تا باشه).
-
هندسه و تقارن: (این شکل چرخیده). رو به صورت ذاتی یا خیلی سریع یاد میگیریم.
اما مدلهای زبانی این چیزا رو “نمیفهمن”. اونا فقط آماری حدس میزنن که پیکسل بعدی چی میتونه باشه. توی ARC، چون هر سوال یه قانون جدید داره که قبلاً دیده نشده، مدلها مثل کسی که شب امتحان هیچی نخونده، شروع میکنن به پرت و پلا گفتن!
پول توش هست! جایزه ۱ میلیون دلاری
این قضیه انقدر برای دنیای تکنولوژی حیاتی شده که یه مسابقه براش گذاشتن به اسم ARC Prize. داستان سادهست: “اگه بتونی مدلی بسازی که این تست رو مثل آدمیزاد حل کنه، بیش از ۱,۰۰۰,۰۰۰ دلار جایزه میگیری!”
چرا انقدر پول میدن؟ چون هر کی این معما رو حل کنه، عملاً کلید AGI (هوش عمومی مصنوعی) رو پیدا کرده. یعنی هوشی که واقعاً میفهمه، یاد میگیره و استدلال میکنه، نه هوشی که طوطیوار تکرار میکنه.
مسیر واقعی به سمت AGI: خداحافظی با طوطیهای سخنگو!
خب، حالا سوال اصلی اینجاست: چرا باید اهمیت بدیم؟
ماجرا اینه که شرکتهای بزرگ (مثل گوگل و OpenAI) فعلاً استراتژیشون اینه: “داده بیشتر، مدل بزرگتر!”. انگار فکر میکنن اگه کل دیتاسنترهای دنیا رو هم به خوردِ مدل بدن، یهو شعور پیدا میکنه. ولی فرانسوا شوله با ARC-AGI داره فریاد میزنه: “این راهش نیست!”.
شما نمیتونید با بزرگ کردن یه طوطی، ازش یه انیشتین بسازید!
آیا به دیوار میخوریم؟
بله، دقیقاً! این بنچمارک نشون میده که روشهای فعلی ما (Deep Learning سنتی) توی “یادگیری و استدلال جدید” ضعف دارن. اگر نتونیم ARC رو حل کنیم، یعنی هنوز به هوش عمومی مصنوعی (AGI) نرسیدیم. یعنی هنوز ماشینی نساختیم که مثل انسان بتونه با دیدنِ دو تا مثال، قانونِ کلِ جهان رو کشف کنه.
این تست، قطبنمای ماست. تا وقتی که اون خط قرمزِ عملکردِ انسانی (Human Level) رو رد نکنیم، هر چی میسازیم فقط یه دستیارِ باهوشه، نه یک موجودِ هوشمند.
خودتون رو محک بزنید!

حالا که تا اینجا اومدید، پیشنهاد میکنم حتماً یه سری به سایت ARC Prize بزنید و چند تا از پازلهاش رو حل کنید. قول میدم همون اولش یه حس غرور بهتون دست میده که “عه! من از GPT-4 باهوشترم!”، ولی بعدش میبینید چقدر مغزِ ما انسانها شاهکاره که این الگوها رو توی کسری از ثانیه میفهمه.
خلاصه کلام: داستان ARC-AGI فقط یه مسابقه نیست؛ جنگِ فلسفه و تکنولوژیه. جنگ بین “حفظ کردن” و “فهمیدن”. و فعلاً… ما انسانها (با اون ۸۵ درصد خوشگلمون) هنوز پرچم رو بالا نگه داشتیم! البته از اونجایی که حوزه هوش مصنوعی دیگه توی ساعت رقابت انجام می شه، این اخبار برای 10 روز اول سال 2026 معتبر بوده، همین الآن از سایت خود ARCPRIZE که روی بنچمارک سوم متمرکز شده می توانید جزئیات بیشتر رو ببینید!
با آخرین و مهمترین اخبار بهروز بمانید
پست قبلی
پست بعدی











استودیو هام



